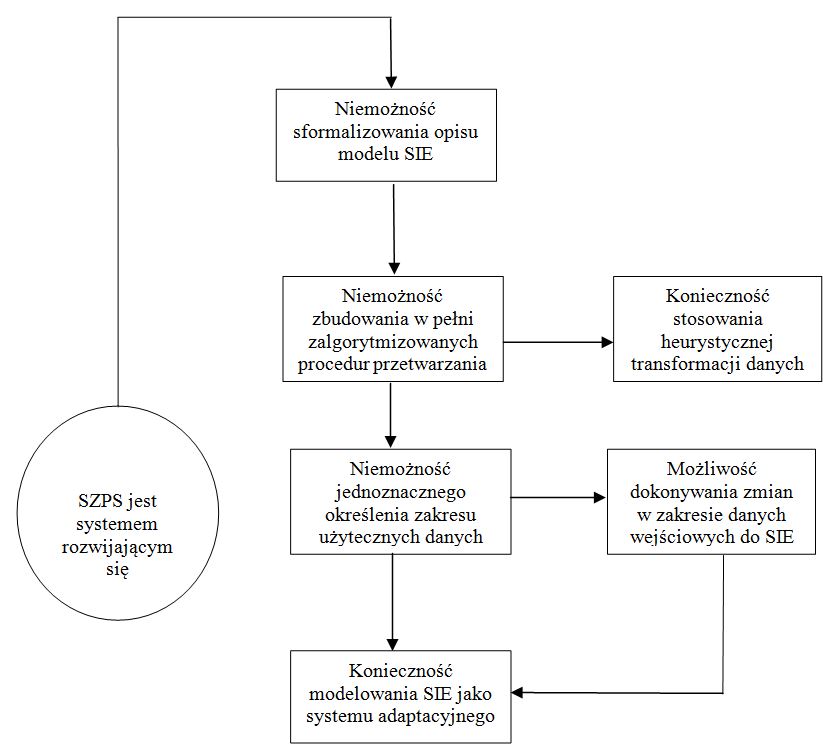
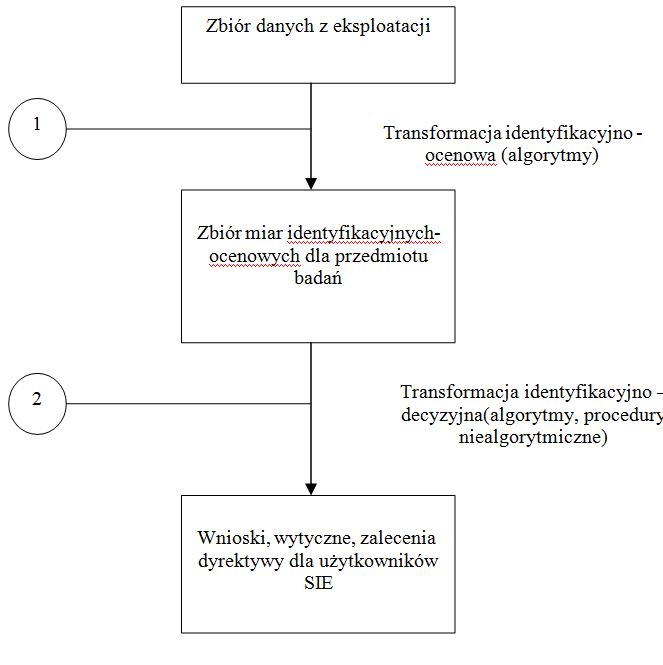
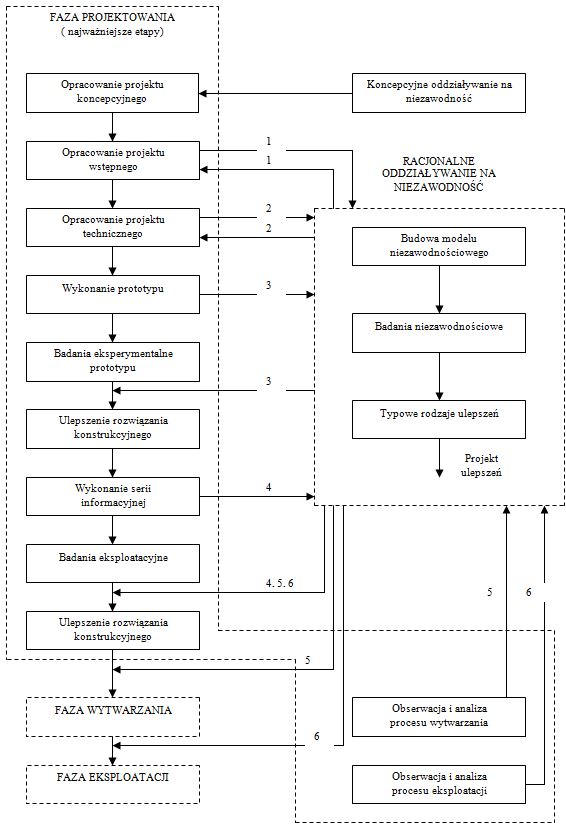
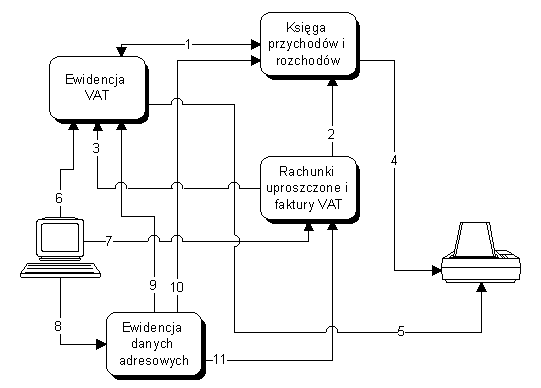
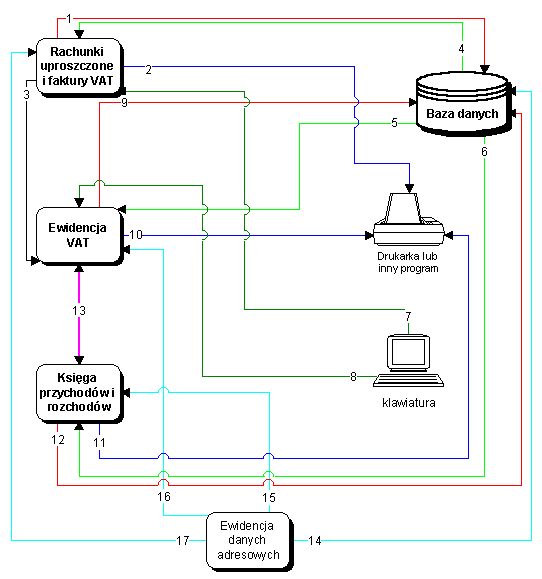
Model tworzenia oprogramowania jest nazywany modelem bazarowym[1], w odróżnieniu od modelu katedralnego[2]. Ten sposób pisania programów został zapoczątkowany i rozwinięty przez członków ruchu OSS. Pierwszym i najbardziej znanym projektem powstającym w ten sposób jest jądro Linux. Obok nieprzeciętnych zdolności przywódczych jego autora – Linusa Torvaldsa, to właśnie przyjęcie modelu bazarowego zadecydowało o sukcesie projektu jaki można obecnie obserwować.[3]
Analizując proces powstawania otwartego oprogramowania łatwo zauważyć miejsca, które stanowią o niezwykle dużym potencjale tej metody:
- Możliwość wykorzystania gotowego projektu.
Twórcy zamkniętego oprogramowania zawsze muszą pisać wszystko od nowa. Wydłuża to czas powstawania programu oraz powoduje związane z tym zwiększenie kosztów. Jednocześnie widać też, że nadążenie kroku za postępem technicznym w takim przypadku jest praktycznie niemożliwe.
- Wykorzystanie pomocy osób z zewnątrz.
Zmniejsza czas i koszty zawiązane z tworzeniem oprogramowania oraz nie wymaga dużego zaplecza informatycznego, dzięki czemu koszty stałe funkcjonowania takiego zespołu projektowego są znacznie niższe niż w przypadku zespołu piszącego zamknięte oprogramowanie.
- Współtworzenie projektu przez przyszłych użytkowników.
Pozwala to na nawiązanie pozytywnych relacji z przyszłymi użytkownikami, którzy będą czuli się współodpowiedzialni za produkt. Dzięki temu pojawi się zjawisko sprzężenia zwrotnego, które znacznie ułatwi proces utrzymania projektu i zmniejszy jego koszty w przyszłości.
- Możliwość łatwego przekazania projektu.
Projekt może funkcjonować niezależnie od pierwotnego zespołu projektowego, gdyż łatwo można przekazać opiekę nad nim. Dzięki temu praca włożona w jego stworzenie nie pójdzie na marne gdy programiści zechcą się wycofać, gdyż o jego życiu nie będą decydować czynniki personalne lub kondycja finansowa grupy projektowej, ale rynkowa przydatność produktu.
Pierwsze narzędzia projektu GNU, pisane przez Richarda Stallmana i innych członków FSF, powstawały według modelu katedralnego.[4] Główna różnica w odniesieniu do Otwartego Oprogramowania między tymi modelami polega na tym, że proces otwarcia następuje praktycznie dopiero po tym, jak pierwotny problem już zostanie rozwiązany. Zespół projektowy działa sam i nie korzysta z pomocy programistów z zewnątrz. Oprogramowanie jest pisane niemal wyłącznie według wizji jego twórców. Przyszli użytkownicy nie mają możliwości uczestniczyć w procesie tworzenia. Po otwarciu projektu mogą oni zgłaszać zauważone błędy, czerpać z kodu źródłowego, dzielić się swoją wizją lub zgłaszać zapotrzebowanie na nową funkcjonalność. Jednak w dwóch ostatnich przypadkach zespół projektowy może nie być skory do ustępstw czy do wprowadzania jakichkolwiek zmian. Zazwyczaj jest już na to po prostu za późno. Projekt był budowany według innych założeń i wprowadzenie takiej zmiany mogło by wymagać zbyt dużego nakładu pracy. Od razu widoczne są tu słabe punkty modelu katedralnego, którego zastosowanie przy tworzeniu otwartego oprogramowania nie pozwala w pełni wykorzystać potencjału jaki dają otwarte źródła.
Według członków ruchu OSS jedynie model bazarowy pozwala uzyskać najwyższe zaawansowanie pod względem technologicznym. Jest to najefektywniejszy sposób tworzenia oprogramowania i tylko on pozwala nadążyć za postępem technicznym. Jednak, jak się okazuje w praktyce, nie jest łatwo w pełni wykorzystać metody otwartego oprogramowania. Wiele programów jest niskiej jakości i często przecząc teorii, ustępują swoim zamkniętym odpowiednikom. Można spotkać się z głosami krytyki i rozgoryczenia ze strony użytkowników zwiedzionych tymi ideami. Jest to problem leżący w założeniach ruchu OSS, na który zwracał w swoich wystąpieniach Richard Stall- man. Dla niego najważniejsza była wolność i to miał być główny atut Otwartego Oprogramowania. Natomiast model bazarowy i korzyści z niego płynące miały być tylko atrakcyjnym dodatkiem, swego rodzaju pozytywną konsekwencją owej wolności. Wiedział, że pełne wykorzystanie tej metody jest trudne i doskonałość technologiczna może w wielu przypadkach pozostać jedynie w sferze teorii. W związku z tym przewidywał, że posługiwanie się jedynie tym argumentem może obrócić się przeciwko środowisku OSS. Dlatego mówiąc o Otwartym Oprogramowaniu trzeba podkreślać, że atutem nie jest tu doskonałość technologiczna, ale potencjał, który wykorzystany odpowiednio pozwoli ją osiągnąć.
[1] Nazwa pochodzi stąd, że tworzenie oprogramowania w ten sposób przypomina funkcjonowanie bazaru. Każdy może przyjść, obejrzeć i dołożyć coś od siebie lub coś zabrać.
[2] Ten sposób pisania oprogramowania przypomina budowę katedry. Architekt w samotności pieczołowicie wznosi jej kolejne warstwy by na końcu, po skończonej pracy, pokazać efekt publiczności.
[3] GNU/Linux stał się poważnym zagrożeniem dla monopolu firmy Microsoft. Coraz więcej firm oraz państw migruje na ten system operacyjny.
[4] Zamknięte oprogramowanie także jest tworzone według modelu katedralnego, jednak oczywiście nie ma tu miejsca otwieranie projektu.
Punkty określają siłę oddziaływania danego czynnika,. Zakres punktacji zawiera się od -5 do -1 dla negatywnych i od 1 do 5 dla pozytywnych czynników.
Waga określa stopień istotności czynnika w danym obszarze analizy.
Sumaryczny wynik może zawierać się w przedziale od -5 do 5.
Punkty określają siłę oddziaływania danego czynnika,. Zakres punktacji zawiera się od -5 do -1 dla negatywnych i od 1 do 5 dla pozytywnych czynników.
Waga określa stopień istotności czynnika w danym obszarze analizy.
Sumaryczny wynik może zawierać się w przedziale od -5 do 5.