Jak już wspominano w rozdz. 2. do działań wchodzących w skład systemu racjonalnego oddziaływania na niezawodność obiektu w fazie jego projektowania należy zaliczyć:
- budowę niezawodnościowego modelu obiektu
- budowanie niezawodności głównie teoretyczne przeprowadzone na zbudowanym modelu
- typowanie najkorzystniejszych rodzajów ulepszeń
Zasady i sposoby realizacji działań a) i b) omówiono szczegółowo w rozdziałach 3, 4 i 5 niniejszej pracy.
Trzecim z podstawowych działań proponowanego systemu racjonalnego oddziaływania na niezawodność (i bezpieczeństwo) obiektu jest typowanie najkorzystniejszych rodzajów ulepszeń. Podstawą do takich działań konstruktora są wyniki badań niezawodności (i bezpieczeństwa), na przykład w postaci wykresów zależności wybranego wskaźnika niezawodności od różnych czynników projektowych, technologicznych i eksploatacyjnych. Ulepszenia polegają głównie na odpowiednich zmianach wartości tych czynników.
W ogólnym przypadku wybór czynnika, którego wartość powinna ulec zmianie, nie powinien być jednak oparty na kryterium niezawodności, gdyż zmiana ta może wywołać nie tylko podwyższenie poziomu niezawodności, lecz również jednoczesne pogorszenie innych cech obiektu, np. bezpieczeństwa, ciężaru, kosztu wykonania, kosztu eksploatacji itd. O wyborze takim powinno więc decydować globalne kryterium oceny obiektu, uwzględniające najważniejsze jego cechy. Jest nią tzw. funkcja dobroci, uwzględniająca różne istotne cechy obiektu, różne ich ważności, a także losową zależność niektórych cech od czasu. Dla czasu t wynosi ona:
(104)
gdzie: Xk(t) jest k-tą cechą świadczącą o dobroci obiektu (ciężar, koszt wykonania Cw, straty wywołane zawodnością C(t), inne koszty eksploatacyjne C (t), zagrożenie [1-B(t)] itd.; wk(t) jest wagą k-tej cechy; xk*(t) jest górną wartością graniczną k-tej cechy (większą od zera), której przekroczenie jest niedopuszczalne lub niepożądane; l jest liczbą. istotnych cech obiektu; J(t) jest wartością zadania wykonywanego przy użyciu obiektu.
Niektóre sposoby ustalania wartości xk* oraz wk są przedstawione w pracy [25]. Ustalanie wartości xk* polega na odpowiednim wyborze tych wartości z zakresu występowania wartości cech Xk obiektów podobnych (do rozpatrywanego) eksploatowanych w podobnych warunkach w jednakowym czasie. Na podstawie umowy oraz pewnych ograniczeń technicznych i nietechnicznych za wartość xk* przyjmuje się największą obserwowaną wartość cechy Xk, jej wartość średnią lub inną, w zależności między innymi od prowadzonej polityki w zakresie postępu technicznego.
Najważniejszą czynnością przy ustalaniu wartości współczynników ważności wk (wg sposobu podanego w [25]) jest uporządkowanie przez zespół ekspertów zbioru obiektów podobnych (do rozpatrywanego) eksploatowanych w podobnych warunkach w jednakowym czasie według na przykład rosnącej dobroci oraz przypisanie im odpowiednich wartości funkcji dobroci. Jest to podstawą do ułożenia odpowiedniego układu równań (104), z którego wyznacza się następnie wartości wk. Taka metoda polegająca na ustaleniu porządku preferencji jest stosowana między innymi w teorii użyteczności.
W wymienionych pracach przyjmuje się za funkcję kryterium, służącą do oceny dobroci, albo wartość oczekiwaną EY funkcji dobroci, albo ryzyko a przekroczenia przez tę funkcję pewnej wartości granicznej (lub przyjętego poziomu odniesienia) y*. Jeśli więc funkcją kryterium, służącą do oceny jest na przykład EY (dla określonego czasu eksploatacji), to zmiany wartości czynnika projektowego, technologicznego lub eksploatacyjnego w celu poprawy niezawodności mają sens, gdy
D(EY) = (EY)2 – (EY)1 < 0 (105)
gdzie indeks „1” oznacza obiekt przed zmianą, a indeks „2” oznacza obiekt po zmianie. Warunkiem decydującym o wyborze rodzaju czynnika do zmiany w pierwszej kolejności jest w tym przypadku warunek
(106)
gdzie
(107)
Indeks „2” oznacza obiekt po zmianach wartości czynnika g, przy czym g należy do zbioru G rozpatrywanych czynników, dla których spełnione są warunki (105).
Metoda kolejnych zmian wartości wspomnianych czynników konstrukcyjnych, technologicznych i eksploatacyjnych (np. zgodnie z warunkiem (106) w kolejności wzrastania D(EY) może być metodą optymalizacji rozwiązania technicznego obiektu o przyjętym schemacie projektowym. Za jej pomocą możliwe jest na przykład wyznaczenie optymalnego rozkładu poziomów niezawodności na poszczególne PK obiektu. W tym celu zmiany poziomów niezawodności poszczególnych PK przez zmiany wartości czynników ze zbioru G należy przeprowadzać dotąd, aż spełnione zostaną w przybliżeniu warunki
(108)
tzn. dotąd, aż zmiany wybranego czynnika nie przestaną poprawiać wartości oczekiwanej funkcji dobroci. To zagadnienie syntezy niezawodnościowej obiektu jest przedstawiane nieco obszerniej w pracach [25].
Wybór najkorzystniejszego rodzaju ulepszenia, odbywający się przy wykorzystaniu warunków (105) i (106), wymaga znajomości matematycznej postaci kryterium, np. wartości oczekiwanej funkcji dobroci (104). W wielu przypadkach o dobroci obiektu decydują tylko względy ekonomiczne, a wartość wykonywanego zadania J(t) nie zmienia się przy zmianie wspomnianych czynników projektowych, technologicznych i eksploatacyjnych. Łatwo uzasadnić , że wówczas funkcja dobroci w postaci (104) może być zastąpiona funkcją
Y(t) = Cw + Ce(t) + C(t). (109)
Jeśli o dobroci obiektu decydują nie tylko względy ekonomiczne, to należy korzystać z postaci (104) funkcji dobroci. Jednakże może być to niewygodne z powodu trudności w określeniu współczynników ważności wk(t). Proponuje się, aby wówczas przy wyborze rodzaju ulepszenia korzystać z funkcji
(110)
gdzie bezpieczeństwo Bb(t). Jeśli zamierzone ulepszenia obiektu nie zmieniają wartości wielkości Bb(t), to w przypadku wspomnianych trudności proponuje się korzystać zamiast z postaci (110) funkcji dobroci – z postaci
(111)
lub z postaci (109).
Algorytm tych podstawowych działań proponowanego systemu jest przedstawiony poglądowo na rys. 8. Na rysunku tym zaznaczone są również ważniejsze sprzężenia w przepływie informacji między tym systemem i różnymi etapami fazy projektowania oraz fazami wytwarzania i eksploatacji. Między innymi wskazane są te etapy fazy projektowania, w których możliwe są racjonalne działania na rzecz niezawodności i bezpieczeństwa obiektu za pomocą systemu przedstawionego w niniejszym opracowaniu.
Wpływanie na poziom niezawodności projektowanego obiektu możliwe jest już we wcześniejszym etapie fazy projektowania, mianowicie w etapie tworzenia i wyboru projektu koncepcyjnego, ale jedynie w sposób jakościowy. Oddziaływanie na poziom niezawodności w tym etapie może być realizowane przez wybór takiej koncepcji, w której przewiduje się:
- małą liczbę elementów, a właściwie – fragmentów obiektu szczególnie narażonych na niesprawności;
- małą liczbę takich fragmentów obiektu, w których szybkość przebiegu zjawisk fizycznych prowadzących do niesprawności może być duża;
- małą liczbę takich fragmentów obiektu, których niesprawności stanowią duże zagrożenie dla ludzi i dla obiektu;
- racjonalne zastosowanie zabezpieczeń, ograniczników i wskaźników;
- łatwą wymianę elementów (profilaktyczną i poawaryjną);
- łatwy sposób diagnozowania;
- modułową konstrukcję niektórych fragmentów obiektu, a nawet całego obiektu;
- małą wrażliwość na błędy wykonania i na błędy eksploatacji itd.
Jak już wspomniano w rozdz. 4, racjonalne oddziaływanie na niezawodność i bezpieczeństwo obiektu, oddziaływanie z zamierzonym i wymiernym efektem, możliwe jest jednak dopiero po wykonaniu projektu wstępnego i zbudowaniu na podstawie tego projektu niezawodnościowego modelu obiektu.
Następnym etapem fazy projektowania, w którym można oddziaływać na tworzony obiekt za pomocą proponowanego systemu jest etap tworzenia projektu technicznego (rys.8). Bywa tak, że ten etap wymusza pewne zmiany w rozwiązaniu projektowym obiektu. Jeśli zmiany te mogą być istotne z punktu widzenia niezawodności, to konieczne jest uwzględnienie ich w modelu niezawodnościowym i zbadanie ich wpływu na poziom niezawodności projektowanego obiektu.
Zaproponowany system może też być wykorzystany do oddziaływania na niezawodność (i bezpieczeństwo) obiektu w pozostałych etapach fazy projektowania oraz w fazach wytwarzania i eksploatacji (rys.8). W tym przypadku wyniki teoretycznych badań niezawodności mogą służyć do potwierdzania i uzupełniania wyników eksperymentalnych badań prototypów i serii informacyjnej oraz wyników eksploatacyjnych badań produkowanych obiektów.
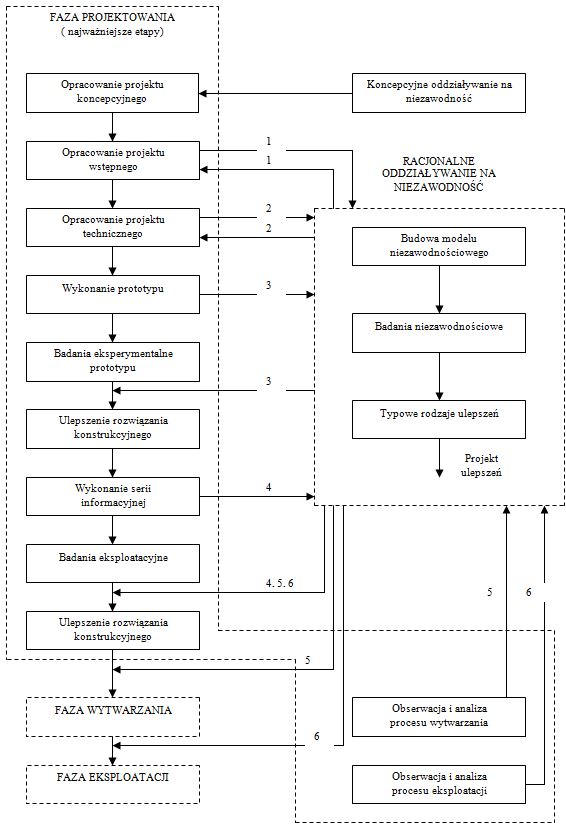
Rys.8. Racjonalne oddziaływanie na niezawodność obiektu w fazie jego projektowania
Celem prowadzenia takich badań jest doskonalenie obiektu w kolejnych etapach i fazach jego tworzenia i istnienia przez: wykrywanie słabych ogniw, wyjaśnianie przyczyn niesprawności, wskazywanie najbardziej efektywnych sposobów doskonalenia rozwiązania konstrukcyjnego obiektu itd.

