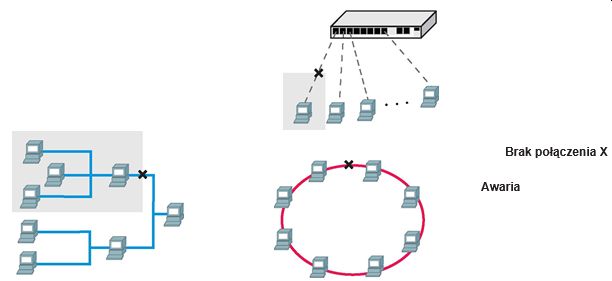
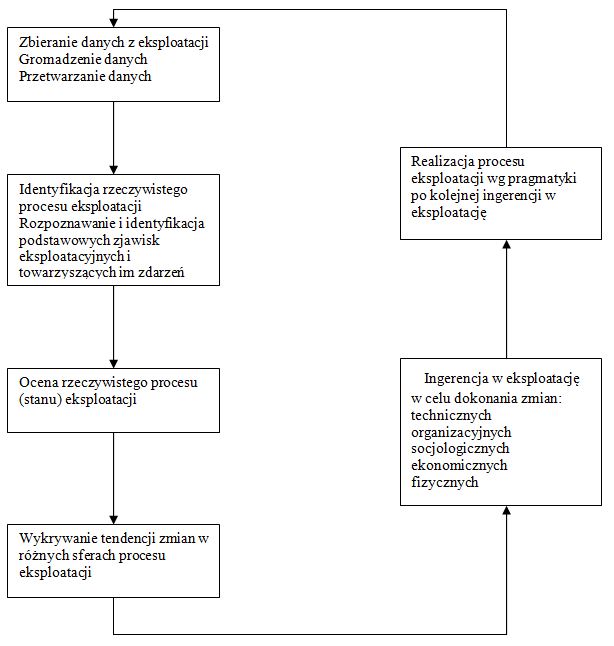
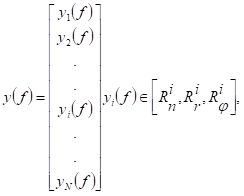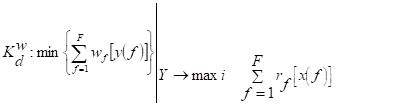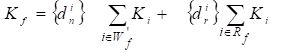Schemat metodyki badań
W obszarze modelowania przedmiotu badań wyodrębnić można cztery zasadnicze, sekwencyjne bloki działań: modelowanie poznawcze, ocenowe, decyzyjne i pragmatyczne (rys. 6.1.).
Rys.6.1. Efekty modelowania przedmiotu badań na podstawie transformacji danych z eksploatacji [9]

Modelowanie poznawcze i ocenowe zaliczyć można do grupy działań identyfikacyjnych.
Modelowanie decyzyjne i pragmatyczne oparte na wynikach modelowania poznawczego i ocenowego realizowane jest pod kątem celów prowadzonych badań. Rysunek 6.1. przedstawia efekty modelowania badanego fragmentu rzeczywistości eksploatacyjnej, którego podstawą są dane z eksploatacji.
Charakterystyka przedmiotu badań
Zgodnie z przyjętą procedurą identyfikacji należy określić elementy główne przedmiotu badań, do których zaliczono:
gdzie:
PB – przedmiot badań,
Ob – obiekt badań, tj. pompy wirowe, eksploatowane w cukrowniach.
Ot – otoczenie obiektu badań rozumiane w sensie tych wybranych charakterystyk rozpatrywanego systemu eksploatacji, które implikują specyfikę użytkowania i obsługiwania badanych obiektów.
Następnie należy określić podzbiory czynników istotnych dla wyodrębnionych elementów głównych:
Ob={CKE, SN, ZSO, Zi},
gdzie:
CKE – zbiór cech obiektu, określonych wg kryteriów:
- konstrukcyjnych (cechy CK)
- eksploatacyjnych (cechy CE)
zatem:
CKE={CK, CE},
SN – struktura niezawodnościowa obiektu
ZSO – zestawienie słabych ogniw obiektu jako rezultat ich identyfikacji (ISO) dokonanej dla ustalonych:
- kryteriów uszkodzeń obiektów (KU)
- kryteriów słabych ogniw (KSO)
zatem:
ZSO={ISO(KU, KSO)}
Zi – zbiór założeń identyfikacyjnych dla badanego obiektu.
Obiektem badań są pompy wirowe, krętne, odśrodkowe jednowirnikowe, poziome, z wirnikiem jednostrumieniowym z wlotem poziomym. Są to pompy typu A, Fy i F produkowane przez WFP, przeznaczone do tłoczenia mediów cukrowniczych. Założono, że struktura niezawodnościowa tych urządzeń składa się z N elementów, połączonych szeregowo. W strukturze niezawodnościowej uwzględniono elementy, które charakteryzują się następującymi cechami:
- a) usunięcie uszkodzenia obiektu wymaga przeprowadzenia demontażu całego obiektu,
- b) szybkość zużywania ściernego elementu wymaga częstej jego wymiany (lub uzupełnianie) w okresach pracy ciągłej, przy czym usunięcie uszkodzenia nie wymaga demontażu obiektu, a zatem:
gdzie:
Ro(t) – funkcja niezawodności obiektu,
R’i(t) – funkcja niezawodności i-tego elementu obiektu,
i= – liczba elementów w strukturze niezawodnościowej obiektu.
Jako uogólnione kryterium uszkodzenia przyjęto następujące określenie stanu niezdatności:
gdzie:
Xj – oznaczenie stanu niezdatności obiektu ( wskutek niezgodności j-tej cechy elementu z wymaganiami)
L – zbiór wszystkich cech elementów obiektu (mierzalnych i niemierzalnych)
M- liczba elementów zbioru L
Mj– oznaczenie elementu zbioru L, j=
– wartość cechy odpowiadająca elementowi M
Wj– wymagania sformułowane w odniesieniu do cechy Mj
W przedstawionym ujęciu stanu niezdatności wszelkie odstępstwa cech elementów (zarówno mierzalnych jak i niemierzalnych) od ustalonych dla tych cech wymagań traktowane są jako uszkodzenia obiektu.
Z uwagi na specyfikę wymogu bezawaryjnej pracy ciągłej w zdeterminowanych okresach jako słabe ogniwa należy traktować:
- elementy, których niezawodność z uwagi na wymagany okres pracy ciągłej jest za niska, czyli:
tB – zdeterminowany okres pracy ciągłej
- elementy, których resurs użytkowy ( określony wartością oczekiwaną czasu ich bezawaryjnego użytkowania ciągłego w kolejnych okresach tB) nie stanowi całkowitej wielokrotności tych okresów, czyli:
Wyeliminowanie słabych ogniw określonych według kryteriów (a) możliwe jest dzięki zmianom konstrukcyjnych, w tym materiałowym lub technologicznym. Możliwość wyeliminowania słabych ogniw w sensie kryterium (b) leży w sferze suboptymalizacji strategii odnowy, w odniesieniu do tych elementów.
W celu dokonania opisu otoczenia obiektu badań, należy ze zbioru elementów stosowanych do opisu systemu eksploatacji oraz ze zbioru charakterystyk realizowanego w nim procesu eksploatacji, wyodrębnić zbiór czynników istotnych.
Do najczęściej stosowanych sposobów definiowania systemów eksploatacji w ujęciu formalnym należy następujący sposób [14]:
SE=< E, D, R, G, H>
gdzie:
E – repertuar eksploatacyjny (może być scharakteryzowany poprzez <SU(X), SO(Y)>)
D – baza eksploatacyjna
R – rozkład eksploatacyjny obiektu (relacje określone na iloczynie kartezjańskim E´D)
G – graf eksploatacyjny obiektu (relacja określona na E´E lub D´D)
H – porządek eksploatacyjny
W celu dokonania opisu otoczenia obiektu badań należy ze zbioru elementów, stosowanych do opisu systemu eksploatacji oraz zbioru charakterystyk,
Rys. 6.2. Charakterystyka chronologiczna funkcjonowania obiektu badań [9]
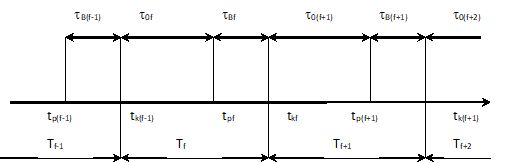
tB – zdeterminowane okresy pracy ciągłej,
tof – zdeterminowane okresy remontowe,
Tf – cykl eksploatacyjny Tf=tof +tBf= (365 V 366) dni,
tBf/tof =1/3 oraz tBf=tB(f+1)=…tB=const. , tof=to(f+1)=…to=const.
tpf – początek okresu pracy ciągłej,
tkf – koniec okresu pracy ciągłej,
tBf=[tpf,tkf]; tof=[tk(f-1),tpf]
realizowanego w nim procesu eksploatacji, wyodrębnić zbiór czynników istotnych. Otoczenie obiektu badań zostało scharakteryzowane następującym zbiorem czynników istotnych
gdzie: H – porządek eksploatacyjny obejmujący:
- charakterystykę chronologiczną funkcjonowania obiektu badań (rys. 6.2),
- harmonogram funkcjonowania obiektu badań
Su(X)- podsystem użytkowania, X – repertuar użytków,
So(Y) – podsystem obsługiwania, Y – repertuar obsługi
R(t) – charakterystyka potencjału eksploatacyjnego.
Opis podsystemu użytkowania.
W rozpatrywanym systemie eksploatacji podsystem użytkowania Su(X) ma charakter zdeterminowany. Pominięto rozpatrywanie tego systemu z uwagi na aprioryczne określenie warunków i sposobu użytkowania.
Opis podsystemu obsługiwania
W podsystemie obsługiwania wyróżnić można następujące rodzaje obsług:
S01 – zabiegi konserwacyjno-regulacyjne (stały dozór, kontrola i regulacja parametrów użytkowania) w okresach tB,
S02 – naprawa poawaryjna w okresach tB,
S03 – planowe remonty w okresach t0 (niezależnie od stanu niezawodnościowego urządzenia).
Potencjał eksploatacyjny obiektu badań
W celu scharakteryzowania potencjału eksploatacyjnego obiektu badań posłużono się analitycznym opisem wykresu przebiegu resursu eksploatacyjnego dla i-tego elementu urządzenia. Wykres przebiegu resursu przedstawia rysunek 6.3.
Wybór takiego rodzaju charakterystyki rozpatrywanego procesu eksploatacji podyktowany został tym, iż:
– w prosty sposób obrazuje ona zdeterminowaną cykliczność procesu eksploatacji badanego obiektu z równoczesnym stochastycznym charakterem uszkodzeń jego elementów,
– rozważania na bazie przebiegu resursu wyodrębnionych elementów stanowią, dla badanych obiektów, podstawę sformułowania zasad suboptymalnej strategii odnowy.
Rys. 6.3. Charakterystyka resursu eksploatacji i-tego elementu obiektu w kolejnych cyklach eksploatacyjnych [9]
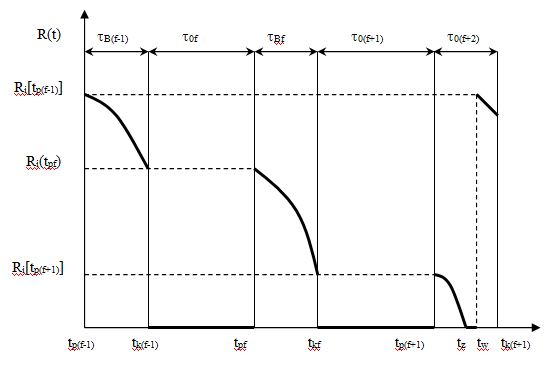
Potencjał eksploatacyjny obiektu z uwagi na resursy jego wyodrębnionych elementów wynosi:
gdzie:
R(tpf)- zasób resursu i-tego elementu na początku f-tego okresu użytkowania ciągłego
a(t)- intensywność roboczego zużycia resursu w okresach tB
Przebieg resursu dla okresu tB(f+1), w którym nastąpiło uszkodzenie, opisuje zależność:
gdzie:
(tz-tw)- czas postoju urządzenia z powodu uszkodzenia i-tego elementu,
Ri(tw)- wielkość odtworzonego resursu i-tego elementu w wyniku przeprowadzonej obsługi S02.
Resurs użytkowy i-tego elementu do chwili uszkodzenia równa się
gdzie:
fi – całkowita liczba przepracowanych bez uszkodzeń okresów tB przez i-ty element,
ri[tp(f+1)] – współczynnik pozostałości resursu dla chwili początkowej (f+1)-go okresu tB, w którym
Zasady suboptymalnej strategii odnowy
Zasada 1
Wszystkie odnowy elementów, których resurs użytkowy spełnia warunek Ri³tB powinny być wykonywane w ramach obsług S03, czyli wyłącznie w okresach t0 określonych następującymi formułami:
- dla elementów, których resurs użytkowy równa się całkowitej wielokrotności okresów tB
gdzie:
Ri(tpn) –zasób resursu użytkowego elementu nowego,
tpf, tkf –chwila początkowa i końcowa f-tego okresu tB,
fi – całkowita liczba okresów tB, po której należy dokonać odnowy i-tego elementu;
- b) dla elementów, których resurs użytkowy nie równa się całkowitej wielokrotności okresów tB
gdzie:
fi – całkowita liczba okresów tB, po której należy dokonać odnowy profilaktycznej i-tego elementu;
tp(f+1), tk(f+1) – chwila początkowa i końcowa (f+1)-go okresu tB
Na podstawie założenia, że tB=const., zależności powyższe można przedstawić w postaci
gdzie:
tk – tp = tB = const.
Ponadto wykorzystując wprowadzone w poprzednim rozdziale pojęcie współczynnika pozostałości resursu, zasadę tę dla przypadku (b) wyrazić można w następujący sposób:
Jeżeli dla i-tego elementu istnieje takie t’k, że zachodzi warunek ri(t’k)>1, gdzie ri(t’k) jest współczynnikiem pozostałości resursu, obliczonym dla czwili końcowej dowolnego okresu tB, wówczas odnowy profilaktycznej tego elementu należy dokonywać w takich okresach t0Î[tk, tp], dla których ri(tk)=ri(t’k)
Zasada 2
W celu pełnego wykorzystania zasobu resursu trwałość elementów obiektu badań należy maksymalnie wykorzystać możliwość ich odnowy poprzez skuteczną regenerację wielokrotną, przeprowadzoną w okresach t0, w ramach obsług S03. Dla rozpatrywanego procesu eksploatacji badanych obiektów regenerację można uznać za skuteczną, jeżeli odtworzony w wyniku jej realizacji resurs użytkowy i-tego elementu spełnia warunek
gdzie:
Rik(tp) – odtworzony w wyniku k-tej regeneracji resurs użytkowy i-tego elementu, określony dla chwili początkowej tp okresu tB,
k – krotność regeneracji
Formuła powyższa określa równocześnie maksymalną dopuszczalną krotność regenracji.
Przedstawiona w dalszym ciągu „zasada 3” wynika z dążności do zminimalizowania czasu realizacji obsług S0i, poprzez wyeliminowanie przestojów w okresach , spowodowanych brakiem części zamiennych oraz koniecznością oczekiwania na dokonanie regeneracji uszkodzonych elementów lub wykonywania ich przez użytkownika we własnym zakresie. Należy przy tym wyjaśnić, że pomimo iż u podstaw suboptymalnej strategii odnowy leży wyeliminowanie obsług S02, to jednak z uwagi na występowanie elementów słabych ogniw w sensie kryterium „a” nie jest to możliwe bez wprowadzenia zmian materiałowo- konstrukcyjno- technologicznych w odniesieniu do tych elementów. Zmniejszeni czasu obsług S02 do normatywnie określonego minimalnego czasu, niezbędnego do wymiany uszkodzonego elementu stanowi doraźny sposób usprawnienia procesu eksploatacji badanych obiektów.
Zasada 3
Liczba elementów zapasowych w chwili początkowej tpf każdego okresu tBf (dla f=) powinna pokrywać zapotrzebowanie na elementy badanych obiektów w okresie tBf, spełniając warunek:
gdzie:
Zi(tpf) – liczba i-tych elementów zapasowych w chwili tpf,
E[ni(tBf)] – wartość oczekiwana liczby uszkodzeń i-tych elementów urządzenia w okresie tBf.
Praktyczna realizacja tej zasady oparta jest na wyznaczaniu wskażników w ramach funkcjonowania SIE dla badanych obiektów.
Identyfikacja ocenowa
Identyfikacja może występować w dwojakiej formie, jako:
- identyfikacja poznawcza stanowiąca działanie jednokrotne, realizowane podczas modelowania SIE,
- identyfikacja ocenowa realizowana wielokrotnie w trakcie funkcjonowania SIE.
Praktyczna forma realizowania identyfikacji ocenowej polega na wyznaczeniu na podstawie danych eksploatacyjnych różnego rodzaju wskaźników określanych jako parametry lub charakterystyki liczbowe (względnie funkcje tych charakterystyk) stanów niezawodnościowych i eksploatacyjnych. Wskaźniki te mogą występować jako określone kryteria oceny lub optymalizacji, miary, metody, wartościowania itp. Zagadnienie doboru wskaźników ma charakter rozwiązań szczegółowych stosowanych dla określonych rodzajów obiektów.
Spośród wskaźników globalnych najczęściej stosowane są wskaźniki o charakterze miar ocenowych efektywności eksploatacyjnej badanych obiektów w aspekcie ekonomicznym. Obecnie istnieje dość duża liczba wskaźników do oceny niezawodności obiektów technicznych, prowadzenia polityki odnowy, wyznaczania optymalnych harmonogramów badań diagnostycznych itp. Z uwagi na niewystarczający zakres ogólności wskaźników ocenowych, dla określonych wymiernych parametrów eksploatacji, jedyną formą sprawdzenia prawidłowości ich doboru jest weryfikacja ich przydatności na etapie praktycznej realizacji badań eksploatacyjnych, pozwalająca na ustalenia odnośnie:
– praktycznych możliwości szacowania wytypowanych wskaźników z uwagi na zakres, wiarygodność częstotliwość itp. możliwych do uzyskania danych w konkretnym fragmencie badanej rzeczywistości eksploatacyjnej,
– praktycznej przydatności określonych wskaźników jako cząstkowych kryteriów identyfikacji poznawczej czy ocenowej wybranych właściwości badanego fragmentu rzeczywistości eksploatacyjnej.
Jako model ocenowy dla rozpatrywanych obiektów technicznych zaproponowano następujące grupy wskaźników [8], wyodrębnionych wg kryterium stanu:
- Wskaźniki charakteryzujące czas przebywania obiektu w określonym stanie lub podzbiorze stanów np.:
a ) średni czas poprawnej pracy do wystąpienia uszkodzenia:
- elementów nowych
- elementów po k-tej regeneracji
- elementów dorabianych przez użytkownika
- obiektu
b) średni czas obsługi spowodowanej uszkodzeniem się i-tego elementu
c) średni sumaryczny czas obsług obiektu
d) średni czas wybranych obsług obiektu.
- Wskaźniki charakteryzujące szansę wystąpienia lub przebywania obiektu w określonym stanie:
- a) prawdopodobieństwo poprawnej pracy i-tego elementu który w danej chwili był:
– nowy
– po k-tej regeneracji
– dorobiony przez użytkownika
- b) prawdopodobieństwo zdarzenia, że element (obiekt) będący w stanie zdatności w danej chwili przepracuje bezawaryjnie określony okres.
- Wskaźniki charakteryzujące liczbę i częstość zdarzeń w określonym przedziale czasu:
- a) liczba uszkodzeń i-tych elementów, które w danej chwili były
-nowe
-po k-tej regeneracji
-dorobione przez użytkownika
- b) liczba uszkodzeń obiektu określona dla konkretnych okresów
- c) średnia częstość uszkodzeń obiektu
- d) częstość występowania uszkodzeń poszczególnych elementów w stosunku do wszystkich uszkodzeń obiektu
- e) częstość występowania uszkodzeń powodujących określone następstwa w stosunku do wszystkich uszkodzeń obiektu:
– częstość uszkodzeń powodujących krótkotrwały przestój obiektu
– częstość uszkodzeń powodujących długotrwały przestój obiektu
- f) liczba wymian elementów:
-na elementy nowe
-na elementy regenerowane
g) liczba elementów nieodnawianych w poszczególnych okresach.
- Wskaźniki charakteryzujące nakłady związane z przebywaniem obiektu w określonym stanie:
a) wskaźnik nakładów na realizację odnowy obiektu w f-tym etapie sterowania
b) wskaźnik strat związanych z nakładami na usunięcie uszkodzeń zaistniałych w danym okresie
c) wskaźnik strat produkcyjnych spowodowanych awaryjnymi przestojami obiektu
d) wskaźnik strat surowca z powodu nieukończenia zadań produkcyjnych w określonym okresie
e) wskaźnik globalnych strat w danym okresie.
- Wskaźniki kompleksowe, będące funkcjami wymienionych uprzednio wskaźników:
a) syntetyczny wskaźnik poprawności pracy obiektu.