Inicjalizacja programu
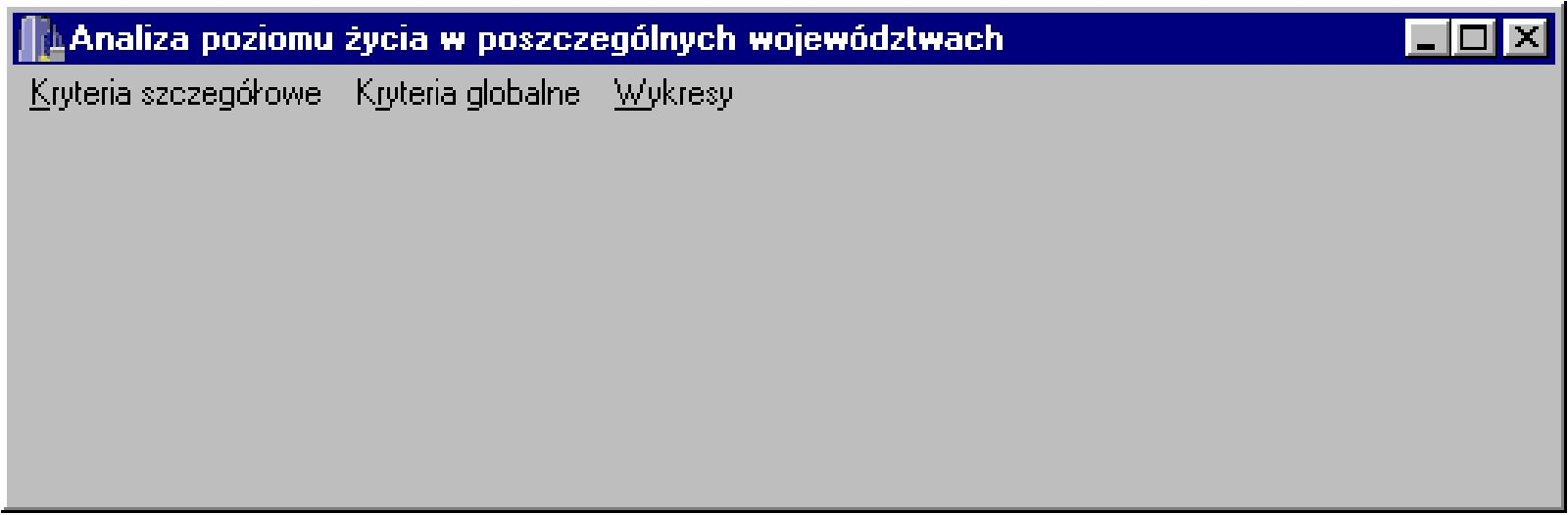
Włączenie aplikacji spowoduje wyświetlenie okna przedstawionego na rys. 4.1.
| Rys. 4.1. Ekran startowy programu. |
Kryteria szczegółowe
Menu Kryteria szczegółowe zawiera pogrupowane dane na temat określonych kryteriów szczegółowych. Menu jest przedstawione na rys. 4.2.
| Rys. 4.2. Podmenu Kryteria szczegółowe. |
Wybór kategorii Zdrowie spowoduje wyświetlenie formularza z danymi dotyczącymi ochrony zdrowia w danym województwie. Formularz taki przedstawiono na rys. 4.3.
| Rys. 4.3. Formularz Zdrowie. |
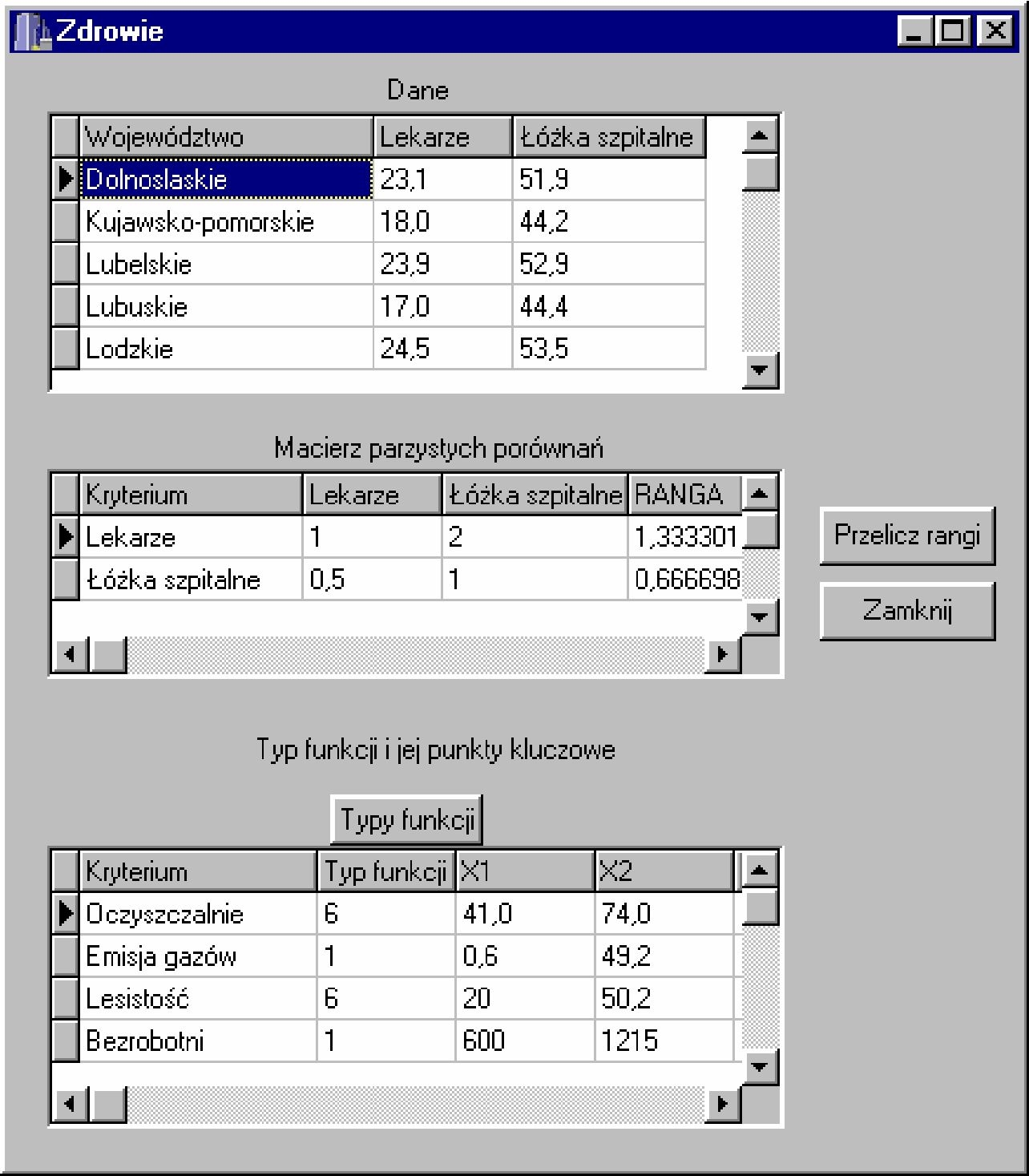
Jak widać na zamieszczonym rysunku formularz ten zawiera dane z trzech tabel: dane dotyczące ochrony zdrowia: Lekarze (liczba lekarzy w danym województwie w przeliczeniu na 10 tys. ludności), Łóżka szpitalne (ilość łóżek szpitalnych w danym województwie w przeliczeniu na 10 tys. ludności). Poniżej jest umieszczona macierz parzystych porównań dla tych danych, natomiast obok tej macierzy jest przycisk powodujący przeliczenie współczynników względnej ważności dla tej macierzy. Przycisk Zamknij powoduje zamknięcie okna. Na dole znajduje się tabela z typami funkcji, które należy przypisać do konkretnego kryterium szczegółowego i punktami kluczowymi funkcji, przycisk Typy funkcji spowoduje wyświetlenie formularza z typami funkcji przedstawionymi na rys. 4.4.
| Rys. 4.4. Formularz z typami funkcji. |

Rys. 4.4. zawiera wszystkie podstawowe typy funkcji użyteczności. Wciśnięcie przycisku Zamknij spowoduje zamknięcie formularza i powrót do formularza z rys. 4.3.
W przypadku wciśnięcia opcji Finanse w podmenu Kryteria szczegółowe przedstawionym na rys. 4.2. zostanie wyświetlony formularz przedstawiony na rys. 4.5. Jak widać formularz ten jest podobny do formularza dotyczącego zdrowia przedstawionego na rys. 4.3. Na górze znajduje się tabela z kryteriami szczegółowymi dotyczącymi stanu finansów w danym województwie: Środki trwałe (wartość brutto środków trwałych w przeliczeniu na jednego mieszkańca danego województwa), PKB (wartość produktu krajowego brutto w zł. w przeliczeniu na jednego mieszkańca województwa), Dochody (wartość nominalnych dochodów brutto w sektorze gospodarstw domowych w zł. na jednego mieszkańca). Niżej umieszczona jest tabela z macierzą parzystych porównań dla tabeli Finanse. Wciśnięcie przycisku Przelicz rangi spowoduje obliczenie współczynników względnej ważności dla kryteriów z tej macierzy. Wszystkie formularze z podmenu Kryteria szczegółowe zawierają wspólne elementy: przyciski Przelicz rangi, Typy funkcji, Zamknij, tabela: Funkcje i punkty kluczowe.
| Rys. 4.5. Formularz Finanse. |

Rys. 4.6. przedstawia formularz Infrastruktura, który zostanie wyświetlony po wybraniu opcji Infrastruktura z podmenu Kryteria szczegółowe. Formularz zawiera tabelę z danymi dotyczącymi stanu infrastruktury w danym województwie: Kolej (linie kolejowe eksploatowane normalnotorowe w km na 100 km2 powierzchni ogólnej województwa), Drogi (drogi publiczne o twardej nawierzchni w km na 100 km2 powierzchni ogólnej województwa), Sklepy (ilość sklepów w danym województwie w przeliczeniu na 10 tys. ludności). Macierz parzystych porównań dotycząca kategorii Infrastruktura jest umieszczona pod tabelą główną, pozostałe elementy są takie same jak we wcześniejszych formularzach.
| Rys. 4.6. Formularz Infrastruktura. |

Rys. 4.7 przedstawia formularz Czystość z podmenu Kryteria szczegółowe. Zawiera on dane dotyczące stanu ekologicznego województwa: Oczyszczalnie (ludność korzystająca z oczyszczalni ścieków w procentach ludności ogółem), Emisja gazów (emisja przemysłowych zanieczyszczeń powietrza gazowych i pyłowych z zakładów szczególnie uciążliwych dla czystości powietrza w tys. ton na 1 km2 powierzchni województwa), Lesistość 30 (powierzchnia gruntów leśnych w procentach powierzchni całkowitej województwa).
| Rys. 4.7. Formularz Czystość. |

Rys. 4.8 przedstawia formularz Praca wywoływany z podmenu Kryteria szczegółowe. Formularz ten zawiera dane dotyczące rynku pracy w danym województwie: Pracujący (liczba osób zatrudnionych w przeliczeniu na 10 tys. ludności w danym województwie), Bezrobotni (liczba zarejestrowanych bezrobotnych w przeliczeniu na 10 tys. ludności w danym województwie), Średnia płaca (przeciętne miesięczne wynagrodzenie brutto w zł. w danym województwie).
| Rys. 4.8. Formularz Praca. |

Rys. 4.9 przedstawia formularz Przestępczość zawierający dane dotyczące stopnia bezpieczeństwa w danych województwach: Przestępstwa (ilość przestępstw stwierdzonych w zakończonych postępowaniach przygotowawczych na 10 tys. ludności), Wskaźnik wykrywalności (wskaźnik wykrywalności sprawców przestępstw stwierdzonych w procentach).
Rys. 4.10 przedstawia formularz Macierz kategorii pozwalający na edycję danych w macierzy parzystych porównań w drugim poziomie hierarchii opracowywanego problemu.
| Rys. 4.9. Formularz Przestępczość. |

| Rys. 4.10. Formularz Macierz kategorii. |

Wybór Kryteriów globalnych z ekranu startowego przedstawionego na rys. 4.1 spowoduje wyświetlenie podmenu Kryteria globalne przedstawione na rys. 4.11.
Kryteria globalne
| Rys. 4.11. Podmenu Kryteria globalne. |

Wybór opcji Zdrowie z podmenu Kryteria globalne powoduje wyświetlenie okna przedstawionego na rys. 4.12. Przedstawia ono tabelę z obliczonymi wartościami kryteriów globalnych dotyczących zdrowia w województwach, tabela przedstawia obliczone wyniki wszystkich trzech kryteriów dla każdego z województw. Naciśniecie przycisku Przelicz kryteria spowoduje ponowne przeliczenie wszystkich kryteriów globalnych dla kategorii Zdrowie. Naciśnięcie przycisku Zamknij spowoduje zamknięcie poniższego okna i powrót do stanu z rys. 4.1.
| Rys. 4.12. Okno Zdrowie – kryterium globalne. |

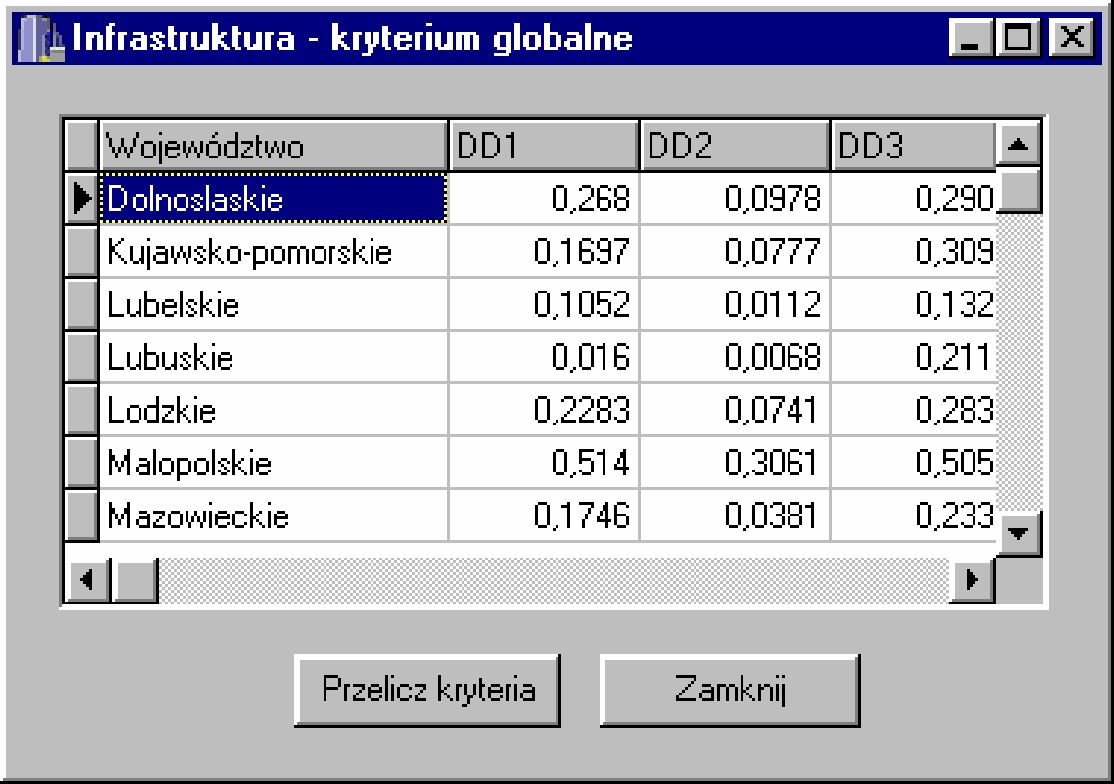
Dla pozostałych kategorii wyświetlanych w podmenu Kryteria globalne przedstawionego na rys. 4.11 wyświetlane są takie same okna. Są one przedstawione kolejno na rys. 4.13, 4.14, 4.15, 4.16, 4.17.
| Rys. 4.13. Okno Finanse – kryterium globalne. |

| Rys. 4.14. Okno Infrastruktura – kryterium globalne. |
| Rys. 4.15. Okno Czystość – kryterium globalne. |

| Rys. 4.16. Okno Praca – kryterium globalne. |

| Rys. 4.17. Okno Przestępczość – kryterium globalne. |

| Rys. 4.18. Okno Wszystko – kryterium globalne. |

Przedstawione na rys. 4.18 okno Wszystko – kryterium globalne zawiera podsumowanie wszystkich kryteriów globalnych w postaci zgodnej z rozdz. 2.2 Trzecim głównym podmenu menu głównego są Wykresy (rys. 4.19). Dostęp do poszczególnych wykresów jest pogrupowany, tak jak do tej pory, w kategorie. Każda z kategorii wyświetla dwa rodzaje wykresów (rys. 4.20) : histogram kryteriów globalnych DD1, DD2 i DD3 konkretnej kategorii dla każdego z województw (rys. 4.21), a także wykres kołowy wskaźnika DD1 konkretnej kategorii dla wszystkich województw (rys.4.22).
Wykresy
Wybór kategorii Zdrowie spowoduje wyświetlenie dodatkowego podmenu z typami wykresów do wyświetlenia (rys. 4.20).
| Rys. 4.20. Typy wykresów do wyświetlenia. |

Wybór opcji Histogram spowoduje wyświetlenie wykresu histogramowego dotyczącego kategorii Zdrowie z podziałem na województwa (rys. 4.21). Kolorem niebieskim oznaczono kryterium globalne DD1, kolorem czerwonym kryterium globalne DD2, kolorem żółtym kryterium globalne DD3. Z kolei wybór opcji Wykres kołowy dla kategorii Zdrowie spowoduje wyświetlenie wykresu przedstawionego na rys. 4.22. Podobnie wyglądają okna wykresów pozostałych kategorii przedstawione na rys. 4.23 – 4.34.
| Rys. 4.21. Histogram kryteriów DD1, DD2, DD3 dla kategorii Zdrowie. |

| Rys. 4.25. Histogram kryteriów DD1, DD2, DD3 dla kategorii Infrastruktura. |

| Rys. 4.27. Histogram kryteriów DD1, DD2, DD3 dla kategorii Czystosc. |

| Rys. 4.29. Histogram kryteriów DD1, DD2, DD3 dla kategorii Praca. |

| Rys. 4.31. Histogram kryteriów DD1, DD2, DD3 dla kategorii Przestępczość. |

Kategoria Wszystko zawiera wykresy histogramowe i kołowe z podziałem na wszystkie trzy kryteria DD1, DD2, DD3. Podział taki wynika z dużej różnicy wyników poszczególnych kryteriów.
| Rys. 4.33. Histogram kryterium DD1 dla kategorii Wszystko. |

| Rys. 4.34. Histogram kryterium DD2 dla kategorii Wszystko. |

| Rys. 4.38. Wykres kołowy kryterium DD3 dla kategorii Wszystko. |