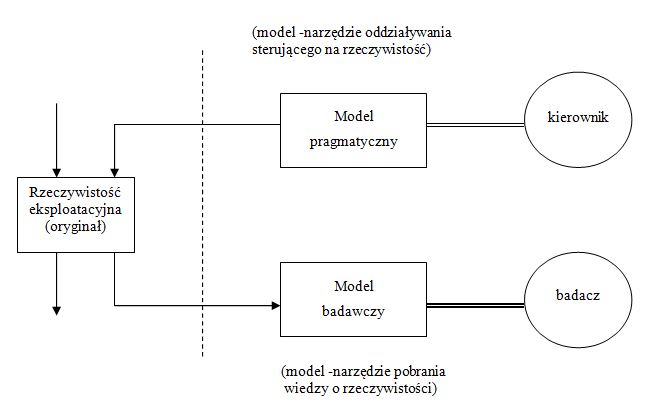
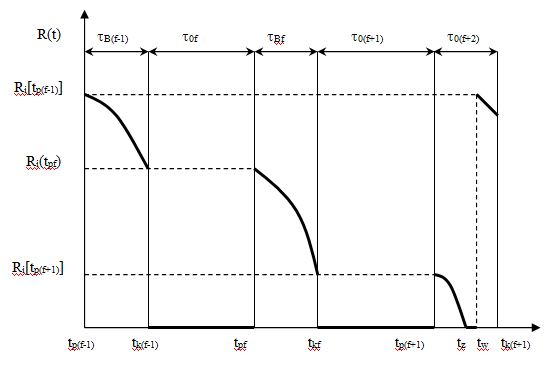
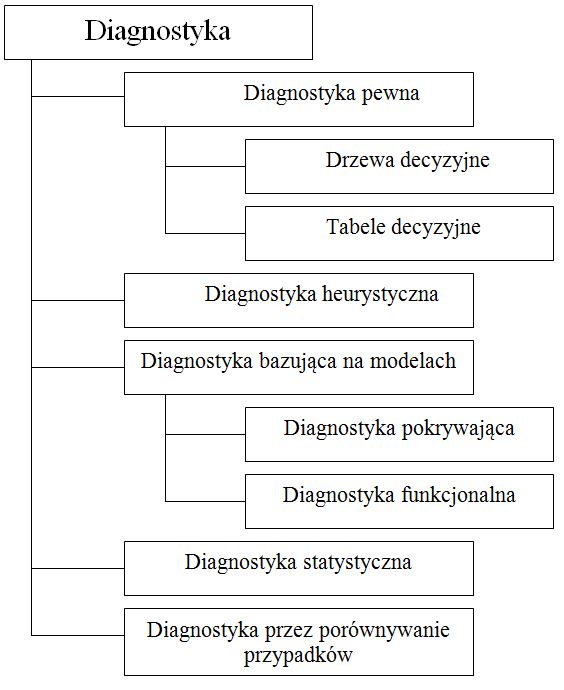
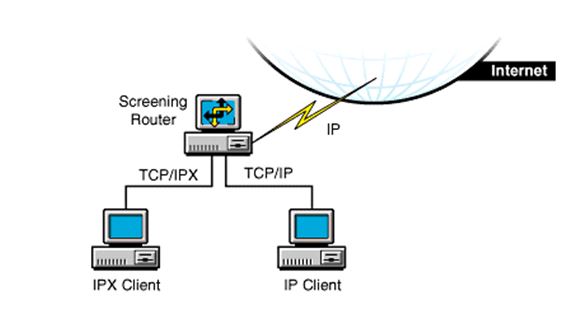
[podrozdział pracy magisterskiej]
Wiedza inferencyjna w systemach ekspertowych jest związana z regułami wnioskowania. Ten rodzaj wiedzy eksploatacyjnej jest potrzebny przy rozwiązywaniu takich problemów, jak np. diagnostyka objawowa i zadaniowa, określanie zakresu naprawy, planowanie użytkowania i obsługiwania. A więc wszędzie tam, gdzie należy podejmować decyzje.
Najbardziej rozpowszechnionym systemem reprezentacji wiedzy inferencyjnej są bazy reguł. Istnieją programy narzędziowe, tzw. ES-Shell (Ekspert-System Shell), tworzące wyspecjalizowane środowisko programowe służące do projektowania systemów ekspertowych.
Chociaż systemy ekspertowe oparte o reguły wymagają silnego zawężenia dziedziny, to w wielu sytuacjach przedstawienie problemu w jednej bazie wiedzy prowadzi do znacznej jej nadmiarowości oraz możliwości konfliktu reguł. Dlatego też, już na etapie konceptualizacji należy przeanalizować możliwość dekompozycji problemu na względnie autonomiczne podproblemy o zróżnicowanym stopniu ogólności, którym odpowiadałyby odrębne bazy wiedzy. Modularność bazy wiedzy stwarza możliwość zanurzania modułów niższego rzędu zawierających wiedzę bardziej szczegółową w modułach wyższego rzędu zawierających wiedzę ogólną. Taka struktura bazy wiedzy jest łatwa do zaimplementowania, ponieważ programy ES-Shell mają możliwość wykonywania komend inicjujących inne bazy. Powstaje w ten sposób możliwość wielotorowości i wieloetapowości procesu konsultacji (wypracowywania porady). Każdy etap procesu konsultacji obsługiwany jest przez odrębny, specyficzny moduł bazy wiedzy wybierany w zależności od danych dostarczanych przez użytkownika i wcześniejszego przebiegu konsultacji.
Z metodologicznego punktu widzenia atrakcyjnym sposobem podejmowania decyzji w przemyśle jest oparcie ich na systemach ekspertowych. Takie systemy pozwalają na doskonalenie wnioskowania w oparciu o tworzone bazy wiedzy, wykorzystujące wiedzę heurystyczną (operatorską), wiedzę proceduralną (modele matematyczne, algorytmy identyfikacji) oraz wiedzę symulacyjną. Systemy ekspertowe maja swoje zastosowanie najczęściej w dziedzinach, które są słabo sformalizowane, tzn. do których trudno jest przypisać teorie matematyczne i zastosować ścisły algorytm działania. Przeciwieństwem są dziedziny, dla których istnieją algorytmy numeryczne. W takim przypadku stosowanie systemów ekspertowych nie jest celowe, gdyż programy algorytmiczne są na ogół znacznie szybsze i doprowadzają do optymalnego rozwiązania, a systemy ekspertowe prowadzą najczęściej do rozwiązań nie koniecznie optymalnych, lecz akceptowalnych przez użytkownika systemu. Zadania systemu ekspertowego w zakresie eksploatacji wynikają z potrzeb użytkownika i można je podzielić na następujące grupy: uczenie, informowanie, doradzanie.
Uczenie jest ukierunkowanym przekazywaniem informacji, być może ze wstępnym testowaniem stopnia ich rozumienia. Wymagana jest tu możliwość wyboru przez użytkownika różnych ścieżek i tempa uczenia w zależności od jego indywidualnych predyspozycji i posiadanej wiedzy. Informowanie jest generowaniem odpowiedzi na predefiniowane grupy zapytań. Doradzanie jest procesem obejmującym wspomaganie przy precyzowaniu problemu oraz generowanie i testowanie hipotez wyjaśniających i operacyjnych (działaniowych). Na przykład, przy wystąpieniu zaburzeń funkcjonowania maszyny, wspomaganie obejmuje: pozyskanie od użytkownika precyzyjnej specyfikacji problemu wraz z kontekstem, wygenerowanie diagnozy, tj. postawienie hipotez odnośnie do przyczyn, zaproponowanie określonych działań regulacyjnych lub naprawczych, ewentualnie dalszych działań sprawdzających.